
Affiliations
Published
June 26, 2024
The past year marked a significant paradigm shift in the ever-evolving landscape of large language models (LLMs), witnessing an unprecedented surge in their popularity, understanding, and capabilities. For instance, proprietary giants like GPT-4 and LlaMA have undeniably captured the attention of the AI community with their ability and versatility. Simultaneously, the emergence of openly accessible yet highly capable LLMs such as LLaMA, Pythia, Falcon, and Mistral have empowered researchers and practitioners to utilize these models in diverse environments and for a multitude of use cases. [1, 2, 3, 4]
However, amidst this surge in accessibility, a concerning trend has emerged. Despite the growing influence of open-source LLMs, there’s a need for greater transparency and access to crucial components of their training, fine-tuning, and evaluation processes. This restricted access poses significant challenges for the broader AI research community, hindering their ability to delve deeper, replicate findings, and innovate upon advanced LLMs. Such limitations underscore the imperative need for a more transparent approach that not only shares final model outcomes but extends to training details and associated artifacts, fostering a more inclusive and collaborative research environment.
Motivated by these challenges, Petuum, in collaboration with MBZUAI, proudly presents the LLM360 framework, a transformative initiative poised to revolutionize the accessibility and transparency of LLMs. At MBZUAI, we are firm believers in the democratization of knowledge and are determined to ensure that all relevant information about LLMs is readily accessible to all.
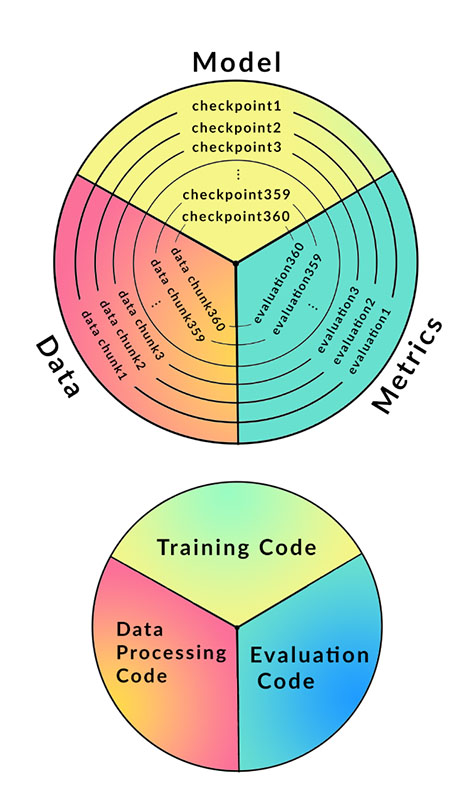
Figure 1: Artifacts released by the LLM360 project include data chunks, model checkpoints, and metrics at over 360-time stamps of training (and code for all parts).
In the paper “LLM360: Towards Fully Transparent Open-Souce LLMs”, the authors address the challenges through a comprehensive open-source LLM effort, ensuring that models are published with all training and model details, including artifacts like intermediate model checkpoints, training data with full data sequence, source code, logs, and metrics. Moreover, LLM360 models are accompanied by all intermediate model checkpoints saved during training, providing unprecedented visibility into the developmental nuances of these models. Our commitment to transparency is further underscored by the entire disclosure of the exact pre-training data used, ensuring clarity and reproducibility in AI research.
Key Highlights of LLM360
1. It outlines the LLM360 framework, emphasizing its design principles and the rationale for fully open-sourcing LLMs. The framework details components such as datasets, code and configurations, model checkpoints, and training metrics, setting a transparent standard for all present and future LLM360 models.
2. It pretrains two new LLMs from scratch—Amber and CrystalCoder—under the LLM360 framework. Amber, a 7B parameter English LLM pretrained on 1.3T tokens, and CrystalCoder, a 7B parameter English and code LLM pretrained on 1.4T tokens, embody the spirit of open-source and transparent AI development.
3. This release includes releasing all training code, pretraining data, model checkpoints, and evaluation metrics collected during pretraining for both Amber and CrystalCoder. Amber is released with 360 model checkpoints saved during training, while CrystalCoder is accompanied by 143 checkpoints.
Release of Amber and CrystalCoder under LLM360
Petuum, in collaboration with MBZUAI, released the first two models under the LLM360 framework: Amber and CrystalCoder. Amber is a 7B parameter English LLM, while CrystalCoder is a 7B parameter code & text LLM. Both models are distributed under the Apache 2.0 license.
Amber: Advancing Knowledge and Transparency in LLM Pretraining

Figure 2: Amber is a 7B parameter English open-source LLM
Amber introduces the start of the LLM360 family, accompanied by its refined iterations: AmberCHAT (An instruction-following model finetuned from LLM360-Amber) and AmberSAFE (A safety-finetuned instruction model using LLM360-AmberChat as the base). Aligned with the LLaMA 7B parameter model architecture and hyperparameters, Amber exhibits commendable performance in MMLU, albeit showing a slight lag in ARC evaluations.
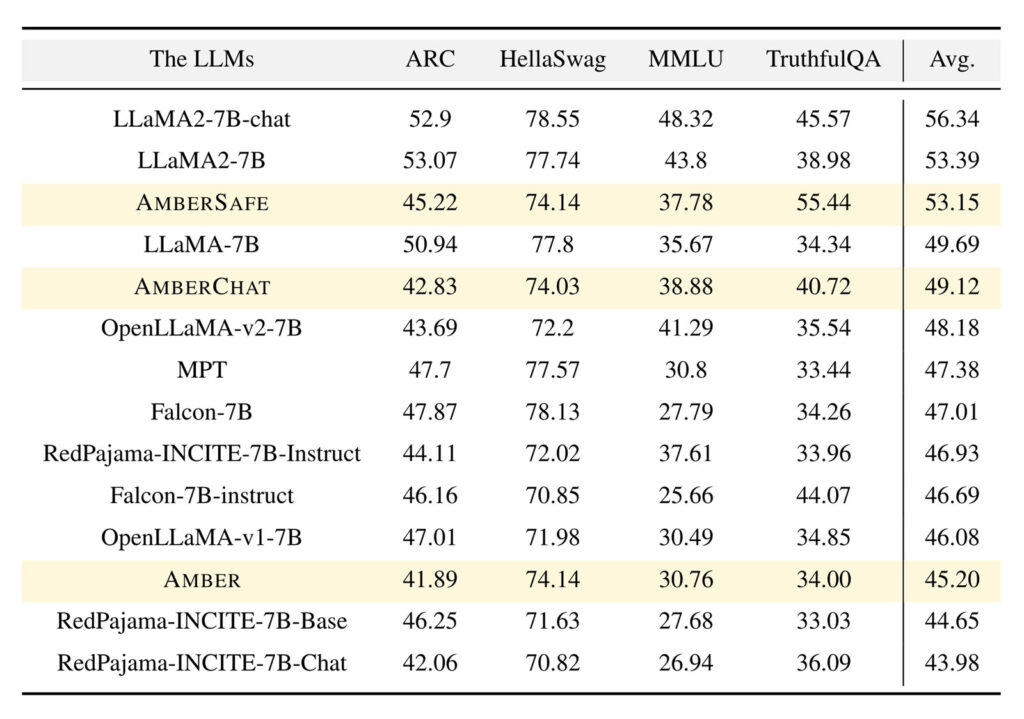
Figure 3: Open LLM leaderboard comparisons for a few LLMs developed around the same time.
What distinguishes Amber from other LLMs is its unique contribution to fostering knowledge exchange between the training team, and the broader community distinguishes it. In addition to the final model weights, Amber is complemented by 359 additional model checkpoints, totaling 360, along with detailed per-step data sequences. Access to these intermediate checkpoints empowers researchers and industry teams, facilitating deeper insights into LLM capabilities and aiding in pretraining or customization for enterprise applications.
Amber’s pre-training dataset, spanning 1.26 trillion tokens, amalgamates diverse datasets for comprehensive coverage, while its architecture mirrors LLaMA 7B, incorporating rotary positional embeddings. Pre-training hyperparameters closely adhere to LLaMA’s specifications, optimizing performance within hardware constraints. Trained on a robust in-house GPU cluster, Amber undergoes meticulous fine-tuning, resulting in models like AmberCHAT and AmberSAFE. Benchmark evaluations highlight Amber’s competitive performance, although with identified areas for enhancement, particularly in ARC evaluations. Challenges such as NaN loss and checkpoint precision discrepancies were addressed iteratively throughout the process, demonstrating MBZUAI’s commitment to refining model stability and accuracy within the LLM360 framework.
To learn more about Amber’s development, take a look at the following resources:
- Data: LLM360/AmberDatasets · Datasets at Hugging Face
- Model LLM360/Amber · Hugging Face
- Code: LLM360 · GitHub
- Metrics: Amber Workspace – Weights & Biases (wandb.ai)
CrystalCoder: Revolutionizing Pre-training and Model Architecture

Figure 4: CrystalCoder is a 7B parameter English and code open-source LLM.
The duo (Petuuum and MBZUAI), in collaboration with Cerebras, also introduced CrystalCoder, a 7B-parameter language model trained on a vast dataset of 1.4 trillion tokens, uniquely blending human language understanding with machine code comprehension. CrystalCoder redefines pre-training methodologies and model architectures, departing from conventional practices like Code Llama by employing a sophisticated three-stage pre-training process. This model combines SlimPajama and StarCoder data to be good at both language and code, with a total of 1382 billion tokens. The pre-training journey unfolds in three stages: initially leveraging half of the SlimPajama corpus, then advancing to incorporate the remaining SlimPajama data along with StarCoder epochs, and culminating in specialized training on Python and web-related data. Furthermore, CrystalCoder’s model architecture mirrors the esteemed LLaMA 7B framework, enhanced with maximal update parameterization (muP) for unparalleled performance. Subtle yet impactful modifications, including the strategic application of RoPE and optimized LayerNorm, amplify computational efficiency and model effectiveness.
This careful process ensures comprehensive coverage, with preprocessed data and mixing scripts readily available in our Huggingface and GitHub repositories. In a comparative evaluation against other prominent language and code models, CrystalCoder demonstrates a remarkable balance across both language and code tasks. Despite being trained on fewer tokens compared to some counterparts, CrystalCoder achieves a competitive position, highlighting its efficacy in handling diverse tasks.
CrystalCoder boasts 143 checkpoints and full pretraining data, positioning it to drive advancements in AI agent capabilities and tool development. Trained on Cerebras’ powerful Condor Galaxy 1 supercomputer, a collaboration between Cerebras and G42, this model embodies MBZUAI’s commitment to pushing the boundaries of language and code integration.
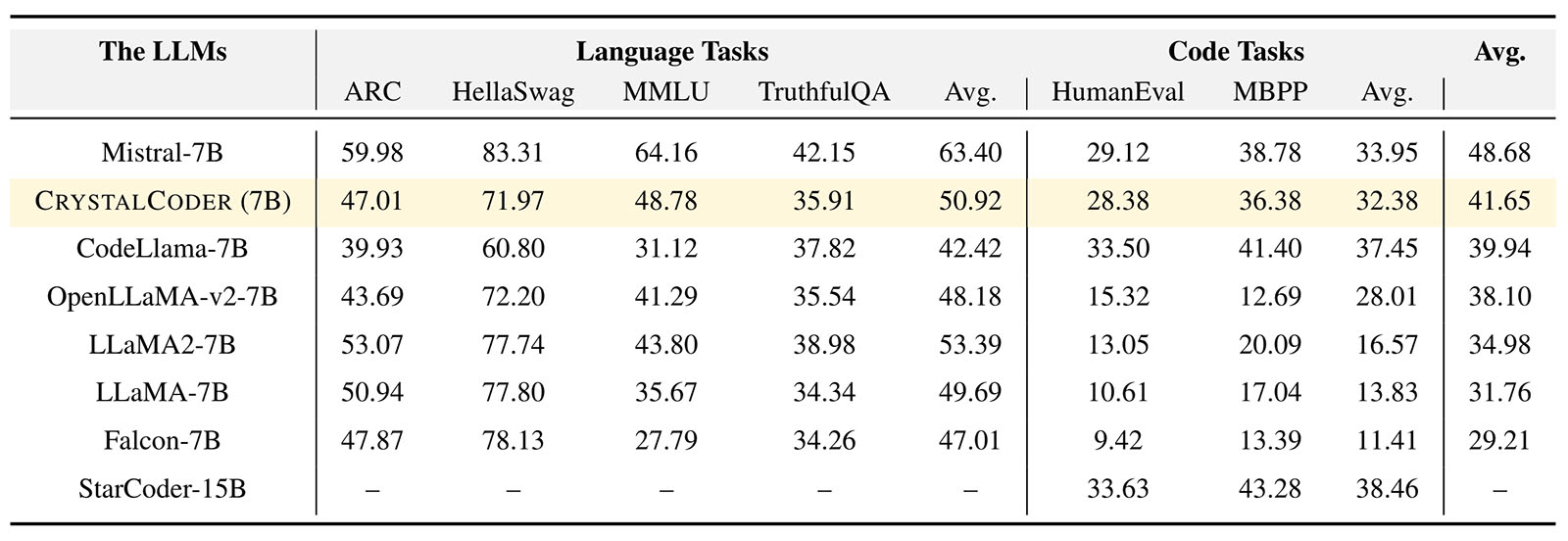
Figure 5: Evaluation comparisons among a few notable code and language models.
We recommend looking at the resources below to learn more about CrystalCoder.
- Data: LLM360/CrystalCoderDatasets · Datasets at Hugging Face
- Model: LLM360/CrystalCoder · Hugging Face
- Code: LLM360 · GitHub
- Metrics: CrystalCoder Workspace – Weights & Biases (wandb.ai)
Key Takeaways
We summarize the key observations from our initial pre-training attempts with Amber and CrystalCoder. Recognizing the computational challenges associated with pre-training, especially for smaller organizations, our aim with LLM360 is to offer comprehensive insights into LLM pre-training processes without the need for users to undertake them independently. Additionally, we outline potential use cases, illustrating how researchers and developers can leverage LLM360 for their projects.
Here are some of the lessons learned from our initial model training:
- During Amber’s pre-training, periodic NaN losses were observed, potentially stemming from random states, training precision, or data quality issues. Strategies such as adjusting random seeds or skipping problematic data chunks were explored, yet challenges persisted.
- Our pre-training efforts with CrystalCoder revealed the efficacy of a hybrid parallelism strategy, combining data, tensor-model, and pipeline parallelism, in achieving superior system throughput, particularly in distributed clusters with limited intra-node bandwidth.
- Data cleaning, quality filtering, and optimal data mixing ratios emerged as critical factors in LLM pre-training. Despite our adherence to LLaMA’s hyperparameters in Amber pre-training, performance still fell short, underscoring the importance of meticulous dataset curation and preprocessing.
We also highlight potential use cases of LLM360, including:
- Conducting experimental studies at various stages of model training to optimize data mixing ratios dynamically.
- Building domain-specific LLMs by resuming pre-training from intermediate checkpoints to obtain tailored models.
- Providing perfect model initializations for algorithmic approximation frameworks requiring partially trained model weights.
Regarding responsible LLM usage, we emphasize the need for stakeholders to address associated risks, such as biases, social stereotypes, and language representation gaps. LLM360’s transparent nature facilitates risk awareness and mitigation by enabling thorough inspection of training data and bias analysis. We are committed to advancing the LLM360 framework to promote responsible LLM usage and welcome collaboration from the community to achieve this goal.
Collaboration and Community
Collaboration and community engagement are central to the ethos of LLM360, fostering a dynamic ecosystem where researchers, developers, and enthusiasts can actively participate and contribute. Here is a concise guide on how you can get involved:
Get Involved:
- GitHub: Our GitHub repository serves as the central hub for all LLM360-related code. Explore, modify, or utilize our codebase, and do not hesitate to contribute your enhancements.
- HuggingFace: Access and download LLM360 models from our HuggingFace repository. Experiment with these models, share your discoveries, and highlight their applications.
Share Your Work:
- Research Contributions: If you have used Amber or CrystalCoder in your research works, we encourage you to share your findings. Your insights can enrich and refine these models, benefiting the broader community.
- Share Results: We welcome your analysis results on any of the checkpoints. Feel free to share computed metrics with us, and selected metrics will be featured on our public Weights & Biases dashboard.
Feedback and Suggestions:
- Feedback Form: Your input is invaluable to us. Utilize our feedback form to share your thoughts, suggest improvements, and express your interests in specific aspects of LLMs.
- Join Discussions: Engage with fellow enthusiasts and experts on our forums. Participate in discussions, pose questions, and exchange ideas to cultivate a vibrant community discussion.
Collaborate:
- Partnership Opportunities: If you are keen on collaborating on a project or have innovative ideas to explore, we are eager to hear from you. Reach out to us to discuss potential partnership opportunities and collaborative endeavors. Together, we can advance LLMs and drive transformative innovations in AI.
LLM360 remains committed to its vision of fully open-sourcing LLMs, with plans to release multiple LLMs of varying scales, performance levels, and domains under the LLM360 framework. As we venture on this journey, we invite researchers, developers, and enthusiasts to join us in shaping the future of AI research—one that is transparent, collaborative, and inclusive.
LLM360’s transformative potential is endless, and we look forward to seeing how it will drive progress in AI research and encourage innovation across diverse domains.
References
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., & Lample, G. (2023). LLaMA: Open and Efficient Foundation Language Models. ArXiv. /abs/2302.13971
- Biderman, S., Schoelkopf, H., Anthony, Q., Bradley, H., Hallahan, E., Khan, M. A., Purohit, S., Prashanth, U. S., Raff, E., Skowron, A., & Sutawika, L. (2023). Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. ArXiv. /abs/2304.01373
- Almazrouei, E., Alobeidli, H., Alshamsi, A., Cappelli, A., Cojocaru, R., Debbah, M., Goffinet, É., Hesslow, D., Launay, J., Malartic, Q., Mazzotta, D., Noune, B., Pannier, B., & Penedo, G. (2023). The Falcon Series of Open Language Models. ArXiv. /abs/2311.16867
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., & Sayed, W. E. (2023). Mistral 7B. ArXiv. /abs/2310.06825
- Liu, Z., Qiao, A., Neiswanger, W., Wang, H., Tan, B., Tao, T., Li, J., Wang, Y., Sun, S., Pangarkar, O., Fan, R., Gu, Y., Miller, V., Zhuang, Y., He, G., Li, H., Koto, F., Tang, L., Ranjan, N., Shen, Z., Ren, X., Iriondo, R., Mu, C., Hu, Z., Schulze, M., Nakov, P., Baldwin, T., & Xing, E. (2023). LLM360: Towards Fully Transparent Open-Source LLMs. ArXiv. /abs/2312.06550


No Comments