
Affiliations
Published
February 04, 2025
Introduction
The rapid growth of 3D data capture technologies like LIDAR and RGB-D cameras has increased the need for automated analysis of 3D point clouds. A key task here is 3D semantic segmentation, where each point in a cloud is automatically labeled with a predefined category. This task is essential for understanding complex scenes and has applications in areas like autonomous vehicles, robotics, industrial automation, and medical imagery.
Recent progress in 3D perception, driven by pre-trained models and new datasets, has made significant strides. However, the ability to reason about 3D contexts remains limited due to a lack of comprehensive datasets for reasoning about 3D scenes and objects. In contrast, combining 2D images and textual descriptions has pushed forward image-language models, though they still struggle with reasoning about 3D object concepts.
Researchers define reasoning capabilities in a model as the ability to understand implicit instructions and justify its responses, whether through text or visual outputs. This reasoning is crucial for more advanced perception systems that can understand and respond to users’ needs without explicit instructions.
In response to these challenges, researchers at MBZUAI have introduced a new task called reasoning part segmentation in 3D. This task involves generating a part segmentation mask for a 3D object based on complex textual queries. To tackle this, they propose PARIS3D (Reasoning-based 3D Part Segmentation), a multimodal Large Language Model that predicts 3D part segmentation masks and explains its reasoning. Alongside this model, the researchers also released a new RPSeg3D dataset containing over 2,600 3D objects and 60,000 instructions to support future research.
Key Contributions
The researchers’ key contributions are:
- Introduce the reasoning part segmentation task for 3D objects, highlighting the importance of reasoning abilities in developing intelligent perception systems.
- Offer a comprehensive dataset, RPSeg3D, with over 2,600 3D objects and 60,000 instructions, providing a valuable resource for future research.
- Present PARIS3D, a novel model for 3D part segmentation enhanced by fine-tuning with the RPSeg3D dataset.
Reasoning 3D Part Segmentation
Traditional semantic segmentation assigns a label to each geometric primitive in a 3D point cloud, such as points or voxels, breaking down object instances into their components. Given a colored point cloud, the goal is usually to predict a label for each point. However, the researchers take this further with their reasoning segmentation task, where the model outputs a 3D segmentation mask based on an implicit query.
This task is more challenging than typical referring segmentation because it requires the model to reason about the fine-grained details of the parts based on complex, implicit queries. Instead of simply naming parts, the queries may include intricate expressions that require an understanding of the structure, geometry, and semantics of 3D objects. By introducing this task, the researchers aim to bridge the gap between user intent and system response, fostering more intuitive and dynamic interactions in 3D object perception.
The RPSeg3D Dataset
Given the lack of established datasets and benchmarks for reasoning 3D part segmentation, the researchers at MBZUAI introduce RPSeg3D, a dataset specifically designed for this task. RPSeg3D includes 2,624 3D objects and over 60,000 instructions. The dataset is divided into a training set with 718 objects and corresponding instructions, and a test set with 1,906 objects and their instructions.
To ensure reliable and fair assessment, the researchers aligned the 3D objects with those from PartNet-Ensemble and annotated them with implicit text instructions. They used ground truth labels to generate high-quality target masks. To create the text instructions, they prepared templates such as “Which part of this object <does this function/looks like this>?” and leveraged GPT-3.5 to build the instructions by providing part information and rephrasing. These instructions were designed to cover relations, dimensions (length, height), comparisons, color, texture features, object concepts, and functions, and were manually verified to avoid inaccuracies.
The instructions in RPSeg3D consist of two types: normal queries and 3D queries. The dataset is partitioned into train and test splits, with the training set containing 16,000 instructions and the test set containing 47,000 instructions, focusing on evaluation purposes.
Reasoning 3D Part Segmentation Architecture
The researchers’ method begins by taking a dense, colored 3D point cloud of an object as input. While traditional 3D analysis relies on point clouds, this approach contrasts with human spatial reasoning, which involves active exploration from multiple perspectives. To mimic this, the researchers advocate for 3D reasoning based on multi-view imagery, leveraging the benefits of large-scale 2D pretraining in vision-language model. The process starts with rendering multiple images from predefined camera angles around the object. These images, along with a complex text instruction, are fed into a multimodal Large Language Model (LLM) and a visual backbone. The LLM generates a text response, while the visual backbone extracts visual embeddings from the images.
For segmentation, the LLM is prompted to produce a binary segmentation mask, where the resulting text output triggers the extraction of an embedding specific to the segmentation task. This embedding is processed through a Multilayer Perceptron (MLP) projection layer and then integrated with the visual embeddings in a decoder to generate the final segmentation mask.
The researchers use a 3D semantic voting module to aggregate the masks obtained from multiple camera angles, assigning semantic labels to each part of the 3D object. They segment the input point cloud into superpoints, which are clusters of points with similar characteristics. This superpoint-based approach conserves computational resources and potentially enhances performance.
In the final step, a view-guided scoring module is used to select the most relevant text explanation for the 3D masks. The module scores each view based on its alignment with the final semantic labels, choosing the explanation with the highest correspondence to the output.
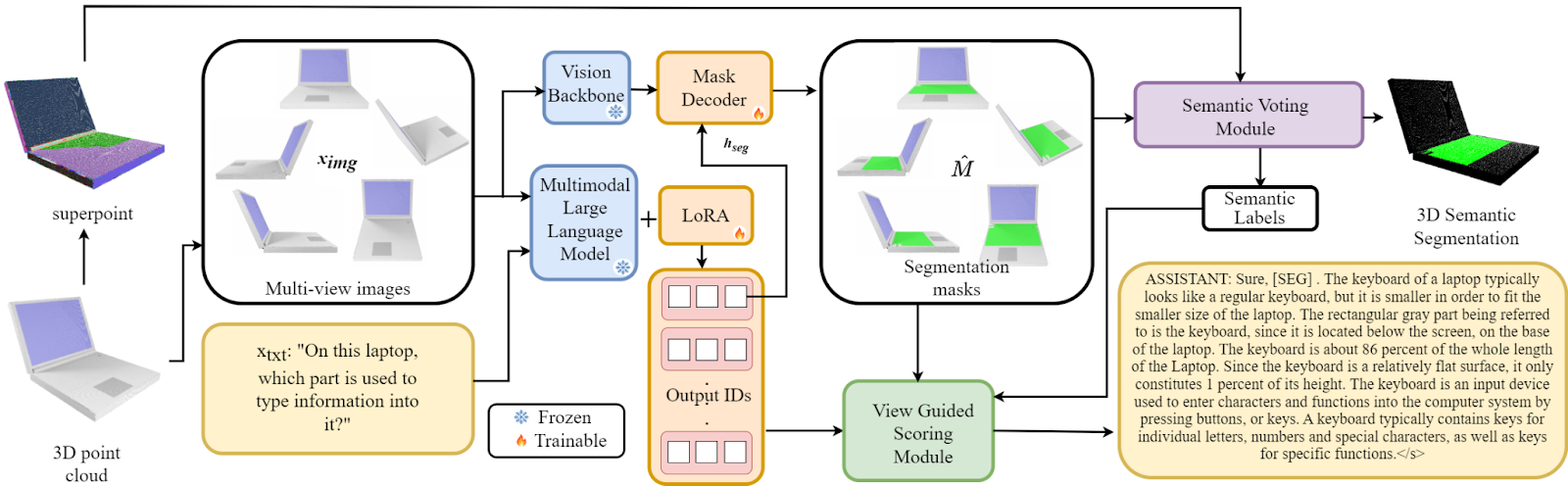
Figure 1: Overview of the proposed reasoning-based 3D part segmentation approach named PARIS3D. It comprises four subsequent steps: (i) The 3D point cloud is rendered into K multi-view images ximg using a renderer. (ii) These images are passed through a frozen vision backbone (Fenc) and multimodal large language model (F) of the reasoning module. F also accepts the text query xtxt, and produces text outputs corresponding to each view. (iii) The decoder decodes the final layer embedding which contains the extra token, thus producing K segmentation masks. (iv) Finally, a mask to 3D segmentation algorithm lifts the projections back into 3D and a view-guided scoring module is used to obtain the final text response.
Training the PARIS3D Architecture
Training Data Formulation
The researchers used 718 3D objects rendered into multiview images, creating over 16,000 image-instruction pairs. Out of these, 360 objects were used for training and 358 for validation. Each image was paired with instructions, an image name, and a ground truth mask. To enhance training, some images were given multiple instructions, introducing variety and helping to build a more robust model.
Distillation-Based Explanation Refining
To train the model effectively, the researchers developed an annotation pipeline using a distillation approach. A teacher model generated explanations for each object part, which served as ground truth for the student model. These explanations were further enhanced with 3D features, focusing on important aspects like location, size, shape, material, and color.
Objective
The researchers fine-tuned the pre-trained multimodal model using a method called LoRA, which allowed them to retain the model’s generalization capabilities while also focusing on the specific meanings and semantic concepts of the parts. They trained the model by combining losses related to text generation and segmentation quality, aiming to improve both the accuracy of the segmentation masks and the relevance of the text explanations.
Experiments
The researchers evaluate PARIS3D quantitatively and qualitatively using their dataset for reasoning-based semantic segmentation.
Implementation Details and Metrics
The researchers use the LLaVA-13B-v1-1 multimodal LLM and the ViT-H SAM vision backbone for their experiments. The projection layer is an MLP with specific channel dimensions. The RPSeg3D dataset includes colored point clouds and their rendered 2D images. Using Pytorch3D, each point cloud is rendered into ten color images.
The fine-tuning is conducted with DeepSpeed, following specific settings for the optimizer (AdamW), learning rate, and other parameters. The semantic segmentation performance is measured using category mean Intersection over Union (mIoU). This metric is computed by calculating mIoU for each part category across test objects and then averaging these values for each category.
Reasoning Part Segmentation Results
The researchers assessed the reasoning-based part segmentation task using the RPSeg3D dataset. The results in Table 2 highlight that the model performs significantly better after fine-tuning compared to its initial state. The findings indicate that 3D queries notably improve mask accuracy. Compared to two baselines—LISA applied to multiple views without fine-tuning, and LISA fine-tuned on few-shot part segmentation data—their method outperforms both, demonstrating superior performance with normal and 3D prompts.
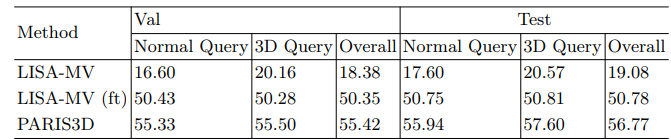
Table 1: Results of reasoning part segmentation. LISA-MV [1] is LISA in multiview setting without fine-tuning. LISA-MV (ft) is the experiment in which it has been fine-tuned on few-shot part segmentation data. Our proposed PARIS3D method has been fine-tuned with 3D queries and explanations. When fine-tuned with 3D information, our model performs better than the baselines for normal and 3D prompts. Here Test is the test set of 1906 shapes and Val is the validation set of 358 3D shapes with their instructions.
3D Semantic Segmentation Comparison with Existing Models
Table 3 compares the semantic segmentation performance of PARIS3D with existing models. PARIS3D outperforms all fully supervised baselines and shows competitive results against other methods. The model demonstrates impressive few-shot performance when prompt tuning is tailored to individual categories. However, when unified into a single model for all categories, its performance only slightly surpasses zero-shot results. This limitation is attributed to overlapping part names across categories, which hinder effective learning.
Unlike baseline models that rely on class IDs or part names for segmentation, PARIS3D uses language instructions for prompting. To ensure a fair evaluation, the researchers employed hand-crafted prompts with concise instructions, leveraging general concepts and location clues.
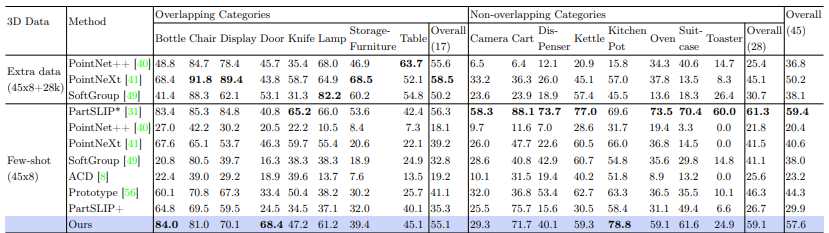
Table 2: Comparison to previous 3D part segmentation methods. Object category mIoU(%) is shown. In the 45×8+28k setting, baseline models use an additional 28k training shapes for 17 overlapping object categories. These are categories present in common with PartNet datset. For the remaining 28 non-overlapping object categories, there are only 8 shapes per object category during training. PartSLIP* indicates that one model has been trained for each category. + shows our implementation of PartSLIP where one model is trained for all the categories together.
Ablation Study
Instruction Rephrasing
The researchers used GPT-3.5 to generate reasoning instructions for training, covering 45 object categories and incorporating color information. They found that fine-tuning with 3D-related data—such as position, shape, and dimensions—was more effective for semantic segmentation compared to fine-tuning solely on reasoning data or color information. The results are detailed in Table 4.

Table 3 presents the results of training the model using different incremental prompts. In the first setting, “GPT-generated,” the training data consists of multiple prompts rephrased by GPT-3.5, focusing on part concepts or functions. In the second setting, “GPT + Colour,” these prompts are enriched with color information related to the 3D train shapes. The final experiment, “GPT + Colour + 3D Info,” involves training the model on multiple rephrased prompts that incorporate color and additional 3D information extracted from the training point clouds.
One Model vs Multiple Models
In their study, the researchers compared the performance of PARIS3D with a baseline model that trained a separate model for each of the 45 categories. As shown in Table 5, PARIS3D demonstrated significant performance improvements under this setting. However, relying on one model per category does not provide a practical solution for real-world applications where multiple object categories and their parts need to be analyzed simultaneously.

Table 4: Results of PARIS3D with one model trained for each of five categories. In comparison to the approach in [4], where 45 models were trained and evaluated individually on their corresponding point clouds, training a model on each category for PARIS3D yields significant performance gains, with improvements of +1.2%, +1.9%, +34.6%, +3.9%, and +47.4% across the tested categories.
Number of Rendered Views
The impact of the number of rendered views on segmentation quality is illustrated in Table 6. With only one view, the segmentations are not meaningful. However, using five views significantly enhances segmentation quality, which improves even further with more views. In the main experiments, 10 rendered views per point cloud are utilized.
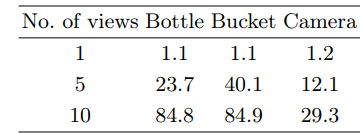
Table 5: Ablation experiments on the number of rendered views.
Single Prompt vs Multiple Prompts
Table 7 presents results from ablation experiments comparing single vs. multiple training prompts. A single prompt uses one concept-based instruction, while multiple prompts involve generating around 5-6 rephrased instructions for each part category. Training with multiple prompts leads to better model performance compared to using a single prompt.
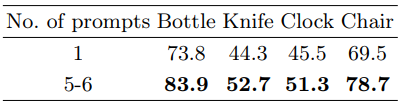
Table 6: Ablation experiments on the number of prompts provided in training data.
Qualitative Results
Figure 5 showcases PARIS3D’s performance in 3D object part segmentation. Based on implicit queries, the researchers demonstrate that the model effectively segments fine-grained details, such as the buttons on a remote or the legs of eyeglasses. It excels at self-reasoning to provide accurate segmentations and can also handle object description and question-answering tasks. This highlights PARIS3D’s strong conversational, reasoning, and segmentation abilities.

Figure 2 presents the capabilities of PARIS3D. Parts of 3D objects are segmented based on reasoning, shape, location, material, colour, and concept instructions. Additionally, for the segmentations, PARIS3D can explain why it chose that region, or describe 3D objects with respect to their parts. The original point clouds are on the left. The segmented parts are shown to the right, highlighted in golden colour.
Generalizability to Real-World Examples
Many 3D segmentation models struggle with real-world data due to their reliance on specific training distributions and difficulty handling the domain gap between synthetic and real-world scenarios. To test PARIS3D’s generalizability, the researchers applied it to point clouds captured with a smartphone’s LiDAR sensor. As shown in Figure 6, PARIS3D successfully segments parts from real-world data with minimal performance drop compared to synthetic experiments. This demonstrates its robustness and versatility in practical applications.

Figure 3 presents qualitative results on real-world examples of point clouds. The input point cloud is shown on the left, with the segmentation mask highlighted in yellow on the right. The model effectively generalizes to point clouds that exhibit a significant domain gap from the training data and demonstrates impressive results in segmenting small object parts, such as the furniture knob in this example.
Conclusion
The researchers introduce a novel challenge in 3D segmentation: reasoning-based part segmentation, which requires models to infer and explain based on implicit user instructions. They present the RPSeg3D dataset to support effective evaluation of this task, believing it will significantly advance technologies in this field. Their approach, PARIS3D, integrates 3D segmentation with multimodal Large Language Models (LLMs) and demonstrates competitive performance. It successfully identifies part concepts, reasons about them, and enhances understanding with world knowledge. However, the current model does not handle instance segmentation, highlighting a key area for future research as they plan to expand the dataset to address this.
To learn more, check out the resources below:

No Comments