
Affiliations
Published
July 30, 2024
Introduction
Large Language Models (LLMs) excel in understanding instructions, generating human-like text, and tackling complex tasks, making them invaluable in various fields, including healthcare. They hold the potential for enhancing diagnostic accuracy through virtual chat support in medical departments. However, their application in healthcare poses challenges, such as the need for domain-specific data, accurate interpretations, and concerns about transparency and bias.
Recent efforts have focused on developing open-source medical LLMs as alternatives to proprietary models like ChatGPT. Yet, leading models like Med42-70B and Meditron-70B have limitations. Med42-70B has not released its training data, and Meditron-70B’s reliance on separate task-specific fine-tuning hinders its versatility. Additionally, many medical LLMs are limited to English, restricting their use in resource-constrained languages like Arabic.
Arabic, spoken by over 400 million people, is underrepresented in medical LLM research. Its unique script and right-to-left format, combined with a lack of large-scale medical training data and evaluation benchmarks, present challenges in developing Arabic or bilingual medical LLMs.
To address these issues, the researchers at MBZUAI introduce BiMediX, a bilingual medical mixture of experts LLM with seamless conversational capabilities in English and Arabic. Below are the key contributions by this paper.
Contributions
- BiMediX Model: The researchers introduce BiMediX, the first Arabic-English bilingual medical mixture of experts LLM with seamless interaction capabilities in both English and Arabic, facilitating multi-turn chats, multiple-choice questions, and open-ended questions.
- Translation Pipeline: The researchers develop a semi-automated translation pipeline with human verification for high-quality translation of English medical text into Arabic, enabling the creation of an instruction-tuning dataset and a comprehensive benchmark for Arabic medical LLMs.
- BiMed1.3M Dataset: They curate the BiMed1.3M dataset, comprising over 1.3 million instructions and 632 million specialized tokens, with a 1:2 Arabic-to-English ratio, supporting diverse medical interactions, including 200k synthesized multi-turn chats.
- Efficient Fine-Tuning: The researchers implement parameter-efficient fine-tuning of Mixtral’s routing and expert layers using BiMed1.3M. BiMediX achieves state-of-the-art performance on multiple medical exam datasets in both English and Arabic, outperforming Med42 and Meditron by 2.5% and 4.1%, respectively in English benchmarks, and the generic bilingual LLM Jais-30B by 10% on Arabic medical benchmarks and 15% on bilingual evaluations.
BiMed1.3M: Bilingual Dataset with Diverse Medical Interactions
The increasing demand for AI-driven medical assistants necessitates comprehensive datasets. These systems must provide concise answers and engage in multi-turn interactions, especially in healthcare, where follow-up questions are common. To meet this need, the researchers compiled an extensive English instruction set.
Compiling English Instruction Set
The researchers assembled a thorough English dataset encompassing three types of medical interactions: multiple-choice question answering (MCQA), open question answering (QA), and multi-turn chat conversations. For MCQA and QA, they consolidated various existing sources into a unified collection of question-answer pairs (detailed in Table 1). To create realistic multi-turn chats grounded in medical accuracy, they utilized ChatGPT’s conversational flow along with publicly available medical MCQAs. This approach simulated doctor-patient dialogues based on medical question-answer pairs, resulting in over 200,000 high-quality multi-turn medical dialogues linked to specific MCQAs, totaling over 74 million tokens.
Following this, the dataset was curated to include over 860,000 instruction-tuning data points in English, covering MCQA, QA, and dynamic chat conversations. Additionally, various publicly available medical benchmark datasets in English were used to evaluate the model’s performance.
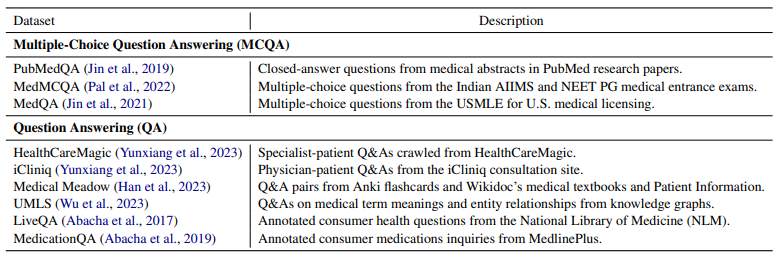
Table 1: Summary of collected data sources for multiple-choice (MCQA) and open question answering (QA).
Next, the researchers introduced a semi-automated iterative translation pipeline detailed below to generate medical evaluation benchmarks tailored for the resource-constrained Arabic language.
Semi-Automated Iterative Translation
The researchers utilized a semi-automated pipeline for translating English benchmarks to Arabic. Initially, a Large Language Model (LLM) like ChatGPT translates the text, considering the entire context to ensure high-quality results. Following this, LLM evaluates the translation’s quality, assigning scores from 0 to 100 based on accuracy and clarity. Translations scoring below a certain threshold are refined iteratively, with LLM updating the translations using feedback. For translations that consistently score low, manual verification is conducted by native Arabic-speaking medical professionals. Additionally, high-scoring translations are randomly reviewed to ensure they meet rigorous standards. This process guarantees high-quality translations that maintain technical accuracy.
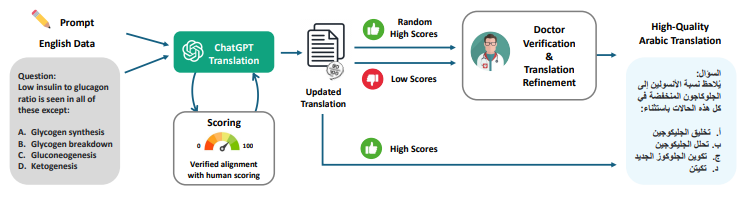
Figure 1: Overview of the proposed semi-automated, iterative translation pipeline featuring human alignment. The process involves iterative translation and score optimization utilizing LLMs (such as ChatGPT) and manual refinement by professionals for samples with low scores along with a random selection of high-scoring samples.
Bilingual Benchmark and Instruction Set
Creation of Medical Benchmark: The researchers have developed a high-quality Arabic medical benchmark by translating established English evaluation benchmarks through an iterative translation procedure. This effort aims to bridge the linguistic gap in evaluating Arabic medical AI models accurately. Combining these benchmarks with their English counterparts, they have created an English-Arabic bilingual benchmark. This allows comprehensive assessment of their bilingual model’s language capabilities and medical domain knowledge, providing a valuable resource for advancing research in this field.
Bilingual Instruction Set: The researchers translated 444,995 English medical samples into Arabic, covering all three types of medical interactions. They used a bilingual approach, mixing Arabic and English in a 1:2 ratio, to create an extensive bilingual instruction tuning dataset. This effort resulted in BiMed1.3M, an English-Arabic bilingual dataset that is 1.5 times larger than its English counterpart, comprising over 1,311,000 samples.
Bilingual Medical Instruction Tuning of Mixture of Experts LLM
The Mixtral architecture introduces a Mixture of Experts (MoE) approach that scales model size efficiently within a fixed computational budget, enhancing performance on general NLP tasks in English. Unlike traditional dense models, Mixtral employs sparse expert layers managed by a routing network, directing input tokens to appropriate experts based on learned parameters. While advantageous for inference speed, Mixtral faces challenges in bilingual medical applications, particularly in Arabic, due to limited domain knowledge.
To address these challenges, the researchers at MBZUAI conducted Arabic-English bilingual medical instruction tuning using their BiMed1.3M dataset. Unlike conventional supervised fine-tuning, which requires significant computational resources and often struggles with generalization, they employed Parameter-Efficient Fine-Tuning (PEFT) techniques like QLoRA-based training. This approach adapted the pre-trained Mixtral model with minimal resources, enhancing its performance and adaptability for bilingual medical chat assistance. Unlike other approaches, they avoided additional medical pre-training before instruction tuning on their dataset.Through meticulous tuning of the Mixtral decoder’s routing network and experts using the BiMed1.3M dataset, the researchers significantly enhanced the model’s capabilities in medical domains in both Arabic and English. This includes improving accuracy in multiple-choice and open-ended question answering, enabling realistic multi-turn interactions between BiMediX and users such as patients, positioning it effectively for deployment as a bilingual medical chatbot.
Experimental Settings
The researchers built BiMediX on the Mixtral-8x7B base network, which is a sparse mixture of experts model. Each layer consists of eight expert feedforward blocks, with a router network selecting two experts to process each token. This configuration manages 47 billion parameters but activates fewer than 13 billion during inference. The model features a hidden state dimension of 14,336, a context window of 32,768 tokens, 32 layers, 32 attention heads, and a vocabulary size of 32,000.
For fine-tuning, the researchers employed QLoRA, a low-rank adaptation technique that adds learnable low-rank adapter weights to the experts and routing network. This method trains about 4% of the original parameters. Their model was trained on 632 million tokens from an Arabic-English corpus, with 288 million tokens exclusively in English. The training utilized an effective batch size of 16, the AdamW optimizer, a learning rate of 0.0002, and a cosine learning rate schedule with ten warmup steps.
The implementation was done using PyTorch, Deepspeed, and ZeRO packages, with gradient checkpointing. Training BiMediX on eight A100 (80GB) GPUs took only 35 hours for two epochs.
Quantitative Evaluation
In evaluating medical language models, the focus often revolves around accuracy in multiple-choice question-answering tasks. The researchers utilized the EleutherAI evaluation framework for their study.
Medical Benchmarks
Their analysis encompassed several significant benchmarks in medical multiple-choice question-answering:
- PubMedQA: PubMedQA (Jin et al., 2019) is a question-answering dataset based on biomedical research papers from PubMed. The task involves answering ‘yes’, ‘no’, or ‘maybe’ to questions derived from research paper titles, using the abstract as context. The researchers focused on the PQA-L subset, which includes manually annotated QA pairs from PubMed, requiring thorough reasoning and data analysis for accurate answers.
- MedMCQA: Constructed from questions found in Indian AIIMS and NEET PG medical entrance exams, this dataset covers a wide range of medical topics and evaluates both domain-specific knowledge and language comprehension. It includes a test set of 4,183 questions, each with four options.
- MedQA: This dataset includes questions from medical board exams across the US, Mainland China, and Taiwan. It features two types of questions: concise sentences to assess specific knowledge and extended paragraphs that detail a patient’s condition. The English portion (USMLE) contains 1,273 samples for testing purposes.
- Medical MMLU: Comprising six datasets—Clinical Knowledge (Cli-KG), College Biology (C-Bio), College Medicine (C-Med), Medical Genetics (Med-Gen), Professional Medicine (Pro-Med), and Anatomy (Ana)—this compilation provides a diverse set of 1,089 test questions across various medical subjects.
To facilitate evaluation across bilingual contexts, all 7,045 questions from these English datasets underwent translation into Arabic using their semi-automated pipeline.
Results
Bilingual Evaluation: The researchers evaluated BiMediX using a bilingual benchmark that assesses performance in both Arabic and English. Table 2 highlights BiMediX’s results compared to Mixtral-8x7B (not fine-tuned) and Jais-30B, a model tailored for Arabic. BiMediX consistently outperforms these models, demonstrating an average accuracy improvement of more than 10 and 15 points, respectively. This outcome underscores the effectiveness of their BiMed1.3M dataset in enhancing the model’s ability to handle medical inquiries across bilingual contexts.

Table 2: Performance of BiMediX on the Bilingual benchmark.

Figure 2: BiMediX is adept at conducting precise medical conversations seamlessly in both English and Arabic. It demonstrates advanced interactive capabilities, such as soliciting further details from the patient and seamlessly switching languages based on patient input while maintaining the continuity of the conversation.
Arabic Benchmark: The researchers evaluated BiMediX using their dedicated Arabic benchmark, comparing its performance against Jais-30B. Table 3 presents the results for both Jais-30B and BiMediX in two configurations: one trained exclusively on Arabic content (Arabic) and another with bilingual data (Bilingual). Across all categories within the Arabic context, their bilingual model consistently outperforms, demonstrating that integrating both types of training data significantly enhances the model’s ability to understand and process medical information effectively in Arabic.

Table 3: Performance of BiMediX on the Arabic benchmark.
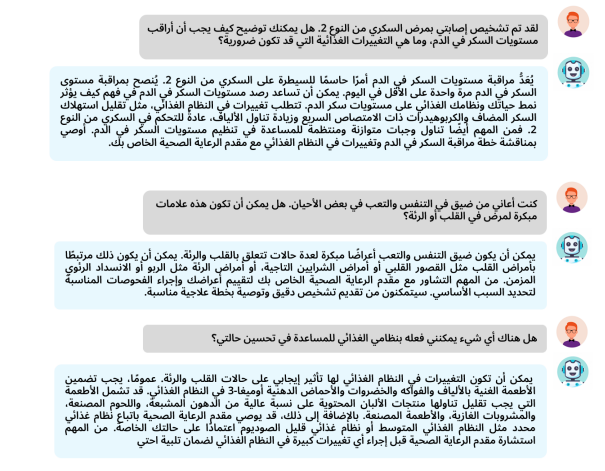
Figure 4: Qualitative Examples of BiMediX

Figure 5: English and Arabic language capabilities of BiMediX with multiple-choice questions and answers (MCQA) on the top row, and open-ended questions and responses (QA) on the bottom row.
English Benchmark: The researchers found that BiMediX demonstrates outstanding performance across all evaluated subsets, securing the highest average scores among state-of-the-art English medical models. Compared to the Clinical Camel-70B model, BiMediX shows an average performance gain of approximately 10%. It also outperforms Meditron-70B in nearly every subset except for MedMCQA. Importantly, BiMediX achieves this without requiring separate fine-tuning for each evaluation benchmark, unlike Meditron, which employs individual fine-tuning strategies. This showcases BiMediX’s versatility in handling diverse medical interactions simultaneously.
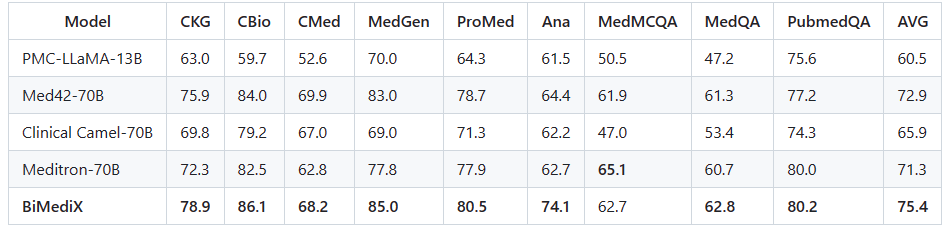
Table 4: Performance of BiMediX on the English benchmark.

Figure 6: Qualitative Examples of BiMediX
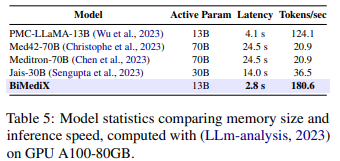
Moreover, our model outperforms Med42 by an average gain of 2.5% and is more efficient in terms of prediction speed (latency and tokens per second) than all other models considered (Table 5).
Conclusion and Limitations
This work introduces BiMediX, the first bilingual medical mixture of experts (LLM), designed to facilitate comprehensive medical interactions in both English and Arabic. Leveraging a semi-automated translation pipeline refined by human experts, BiMediX ensures high-quality English-to-Arabic translations. The model demonstrates superior performance compared to existing models like Med42 and Meditron in English medical benchmarks, and outperforms the generic bilingual LLM, Jais-30B, in Arabic medical and bilingual evaluations. The creation of a novel evaluation benchmark and the extensive BiMed1.3M instruction set, comprising 1.3 million diverse medical interactions, highlights the significance of their contributions to advancing bilingual medical AI.
Despite its advancements, BiMediX, like other language models, faces issues such as hallucinations, toxicity, and stereotypes due to inherent limitations in the models and biases in the data used for training. While evaluations with medical professionals have been conducted, the accuracy of its medical diagnoses and recommendations may vary. Human evaluation is more reliable but expensive and time-consuming. Ongoing research aims to find solutions to these challenges. Currently, BiMediX lacks specific methods to address undesirable behaviors, an area where future studies will focus on improving security and alignment strategies. By sharing these findings, researchers aim to better understand and manage risks associated with practical applications.
The researchers acknowledge the profound societal impact of this technology and emphasize ethical considerations and transparency. While their release is intended for research purposes only and is not yet suitable for clinical or commercial use, further research is essential to ensure safety and accuracy in clinical settings and to mitigate potential patient harm. Collaboration with patients, medical professionals, and ethicists is crucial for robust ethical oversight.
If you want to learn more about BiMediX, check out the resources below:
- Paper: https://arxiv.org/pdf/2402.13253
- Code: https://github.com/mbzuai-oryx/BiMediX
- Offline demonstration: https://github.com/mbzuai-oryx/BiMediX/blob/main/README.md
References
- Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. 2024. Mixtral of experts. arXiv preprint arXiv:2401.04088.
- Neha Sengupta, Sunil Kumar Sahu, Bokang Jia, Satheesh Katipomu, Haonan Li, Fajri Koto, Osama Mohammed Afzal, Samta Kamboj, Onkar Pandit, Rahul Pal, et al. 2023. Jais and jais-chat: Arabic-centric foundation and instruction-tuned open generative large language models. arXiv preprint arXiv:2308.16149.
- Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421.
- Zeming Chen, Alejandro Hernández Cano, Angelika Romanou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Matteo Pagliardini, Simin Fan, Andreas Köpf, Amirkeivan Mohtashami, et al. 2023. Meditron-70b: Scaling medical pretraining for large language models. arXiv preprint arXiv:2311.16079.

No Comments