
Affiliations
Published
July 30, 2024
Introduction
Current methods in video understanding primarily rely on either image or video encoders, each with inherent limitations. Image encoders capture detailed spatial information but lack the temporal context crucial for understanding dynamic actions. On the other hand, video encoders excel at capturing global temporal context but struggle with computational limitations. To manage these constraints, the video resolution is often reduced, and only a small subset of frames is processed. This compromises the level of detail and the richness of spatial and contextual information that can be extracted from the video.
To address these challenges, researchers at MBZUAI introduce VideoGPT+, the first video-conversation model to leverage a dual-encoding scheme using both image and video features. This innovative approach harnesses the strengths of both encoder types, capturing detailed spatial information through the image encoder and comprehensive temporal context through the video encoder.
Unlike the uniform sampling strategy used in existing video models, VideoGPT+ employs a segment-wise sampling strategy to capture fine-grained temporal dynamics. This method divides videos into smaller segments, ensuring representative information from various parts of the video is captured, enabling a more comprehensive understanding.
Additionally, a visual adapter module was introduced to integrate image and video features seamlessly. This module performs projection and pooling operations to align the complementary benefits of both features into a shared space, enhancing the model’s ability to utilize spatial and temporal information while reducing computational complexity effectively.
To overcome the limitations of existing datasets for training video conversation models, the researchers created VCG+ 112K, a video instruction dataset with detailed annotations. This dataset, created using a semi-automatic annotation pipeline, provides detailed video captions, promotes spatial understanding, and includes reasoning-based question-answer pairs. These features significantly enhance the model’s performance compared to existing datasets.
The researchers also introduce VCGBench-Diverse, a benchmark dataset that covers 18 video categories with 4,354 human-annotated QA pairs covering lifestyle, sports, science, gaming, and surveillance videos. This benchmark allows for extensive evaluation of video conversation models across various domains, ensuring a thorough assessment and driving advancements in video understanding technology.

Figure 1: VideoGPT+ outperforms various state-of-the-art models in multiple video benchmarks, including video conversation, zero-shot video question answering, and diverse video categories.
Key Contributions
- Dual-Encoder Design: VideoGPT+ pioneers a dual-encoding scheme combining image and video features, offering rich spatiotemporal details for improved video understanding.
- Enhanced Dataset: VCG+ 112K: Addressing limitations in existing datasets, the researchers develop VCG+ 112K using a novel semi-automatic annotation pipeline. This dataset provides dense video captions, spatial understanding, and reasoning-based QA pairs, significantly boosting model performance.
- New Benchmark: VCGBench-Diverse: Recognizing the need for diverse benchmarks, we introduce VCGBench-Diverse. This benchmark spans 18 video categories with 4,354 human-annotated QA pairs, enabling extensive evaluation of video conversation models across diverse domains.
Method
Combining detailed spatial information with explicit temporal context is crucial to understanding videos. VideoGPT+ features a dual encoder design that uses the strengths of both image and video encoders. VideoGPT+ consists of four main components:
- Segment-wise Sampling: Selects frames from different segments of the video.
- Dual Visual Encoder: Processes frames using both an image and a video encoder.
- Vision-Language Adapters: Converts visual features into a format understandable by a language model.
- Large Language Model (LLM): Integrates visual and text features for comprehensive video understanding.
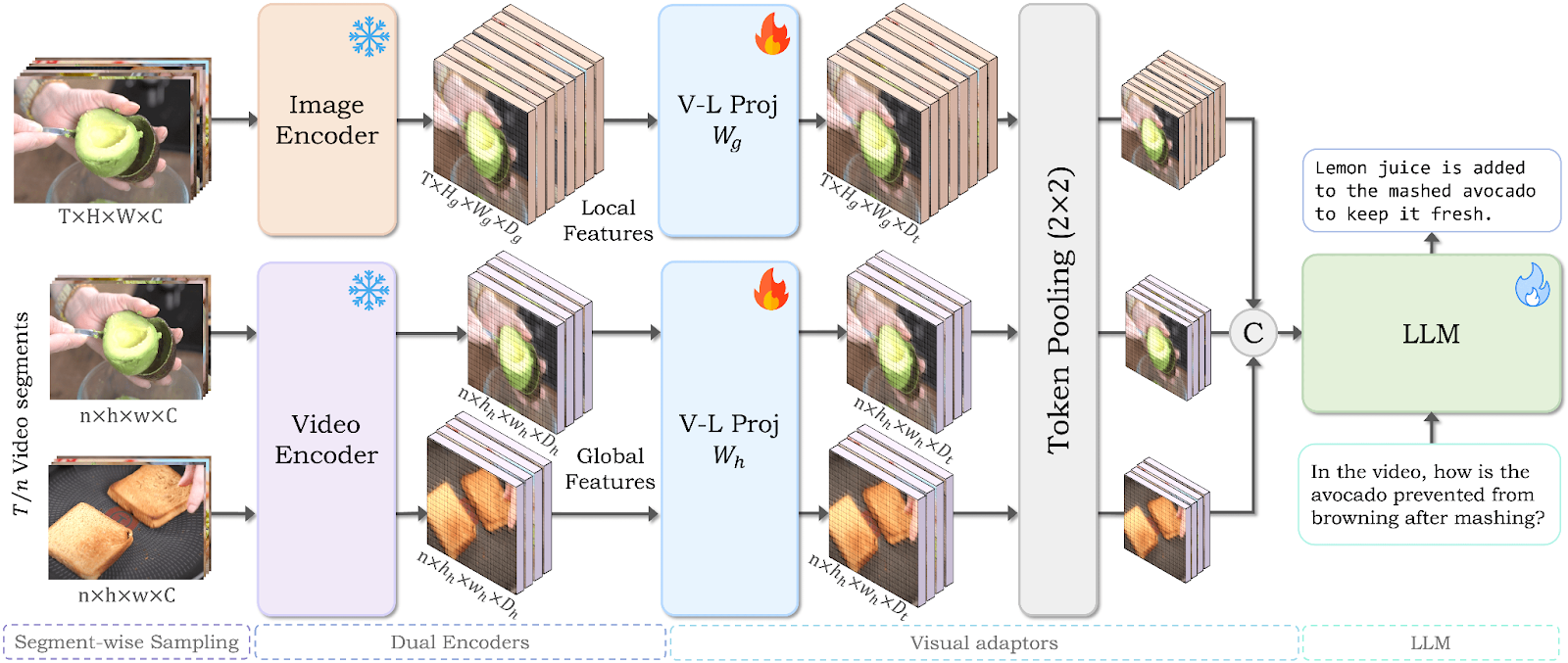
Figure 2: Overview of VideoGPT+, a large multimodal model for video understanding. It uses a dual-encoder design, with an image encoder for spatial features and a video encoder for temporal dynamics. It combines these through Vision-Language projection layers to generate comprehensive responses to video-based questions.
Segment-wise Sampling: VideoGPT+ divides the video into segments to capture fine-grained temporal details. This ensures that encoders process data efficiently and effectively.
Dual Vision Encoder: The image encoder captures detailed spatial features from individual frames, while the video encoder provides broader temporal context from the segments. The researchers use pre-trained models (CLIP for images and InternVideo for videos) to use their robust performance.
Visual Adapter: The visual features from the encoders are projected into the language space using Vision-Language adapters. These adapters transform the visual data into a format the LLM can process.
Large Language Model: The final step combines the spatial features from the image encoder, the temporal features from the video encoder, and the user text query into a single sequence. The LLM then processes this integrated representation to understand the video comprehensively. The researchers fine-tune the LLM to improve its performance in predicting the next tokens in the sequence, ensuring a seamless understanding of the video content.
Dataset
The VideoInstruct100K dataset, introduced by Video-ChatGPT (a video conversation model developed by MBZUAI), uses a semi-automatic annotation pipeline to create 75K instruction-tuning QA pairs. To address the limitation of the annotation process, MBZUAI researchers developed the VCG+ 112K dataset with an improved annotation pipeline using enhanced keyframe extraction, detailed descriptions using advanced models, and refined instruction generation.
Keyframe Extraction: The researchers improve on VideoInstruct100K by extracting scenes from videos and selecting one keyframe per scene. This method captures detailed information for complex videos and reduces redundancy for simpler ones, offering a more accurate visual representation.
Frame-Level Descriptions: LLaVA-v1.6 was used to generate detailed descriptions for each keyframe, capturing comprehensive visual details like spatial attributes, scene context, and object characteristics. These enhance the precision of ground truth captions by adding granular information, improving video descriptions’ overall quality and accuracy.
Detailed Video Descriptions: The researchers strengthen the process of generating QA pairs by creating detailed and coherent video descriptions. They use GPT-4 to integrate frame-level descriptions with ground truth captions, resolving inconsistencies. This results in comprehensive descriptions that include timelines, actions, object attributes, and scene settings, simplifying the task for language models and enhancing the quality of the generated QA pairs.
Improved Instruction Tuning Data: Using the refined descriptions, two types of QA pairs were generated with GPT-3.5: descriptive and concise. Descriptive pairs cover dense captioning, detailed temporal information, and in-depth questions. Concise pairs focus on spatial reasoning, event reasoning, and specific temporal questions.

Figure 3: Illustration of the semi-automatic annotation process in VCG+ 112K, where ground-truth video captions and frame-level descriptions are refined by GPT-4 to create detailed video descriptions. This process integrates spatial, temporal, event, and reasoning details, which are then used to generate instruction-tuning QA pairs with GPT-3.5, improving the quality compared to the VideoInstruct100K dataset.
Proposed Benchmark: VCGBench-Diverse
In response to the limitations of existing benchmarks, the project introduces VCGBench-Diverse to enhance the evaluation of video Language Model Multimodalities (LMMs). This benchmark expands the scope of evaluation provided by VCG-Bench by incorporating a diverse range of videos and evaluation criteria.
Video Diversity: VCGBench-Diverse includes 877 videos spanning 18 broad categories such as lifestyle, science and technology, entertainment, sports, and more. This ensures a comprehensive evaluation across various real-world scenarios.
Capture Methods: The benchmark covers five video capture methods, including static and controlled settings, dynamic and unpredictable settings, fixed camera perspectives, professional and high-quality videos, and uncontrolled and variable quality, ensuring robustness to different filming techniques and conditions.
Reasoning Complexities: VCGBench-Diverse evaluates models across six reasoning complexities: sequential understanding, predictive reasoning, contextual knowledge, causal reasoning, narrative reasoning, and analytical reasoning. This provides a holistic assessment of model capabilities in understanding diverse video content.
Annotation Process: Videos from HDVILA, MPII, YouCook2, UCF Crime, and STUD Traffic undergo detailed annotation by human annotators familiar with audio and visual elements. Annotations are subject to meta-review for accuracy and consistency.
Methodology: Human annotations are the basis for generating QA pairs using GPT-3.5, ensuring the benchmark’s relevance and rigor.
Evaluation Metrics: Following VCG-Bench standards, evaluation covers the correctness of information, detail orientation, contextual and temporal understanding, and consistency. Additionally, performance is assessed in dense video captioning, spatial understanding, and reasoning.
This structured approach in VCGBench-Diverse aims to provide a robust framework for evaluating the generalization ability and performance of video LMMs across diverse and challenging video datasets.
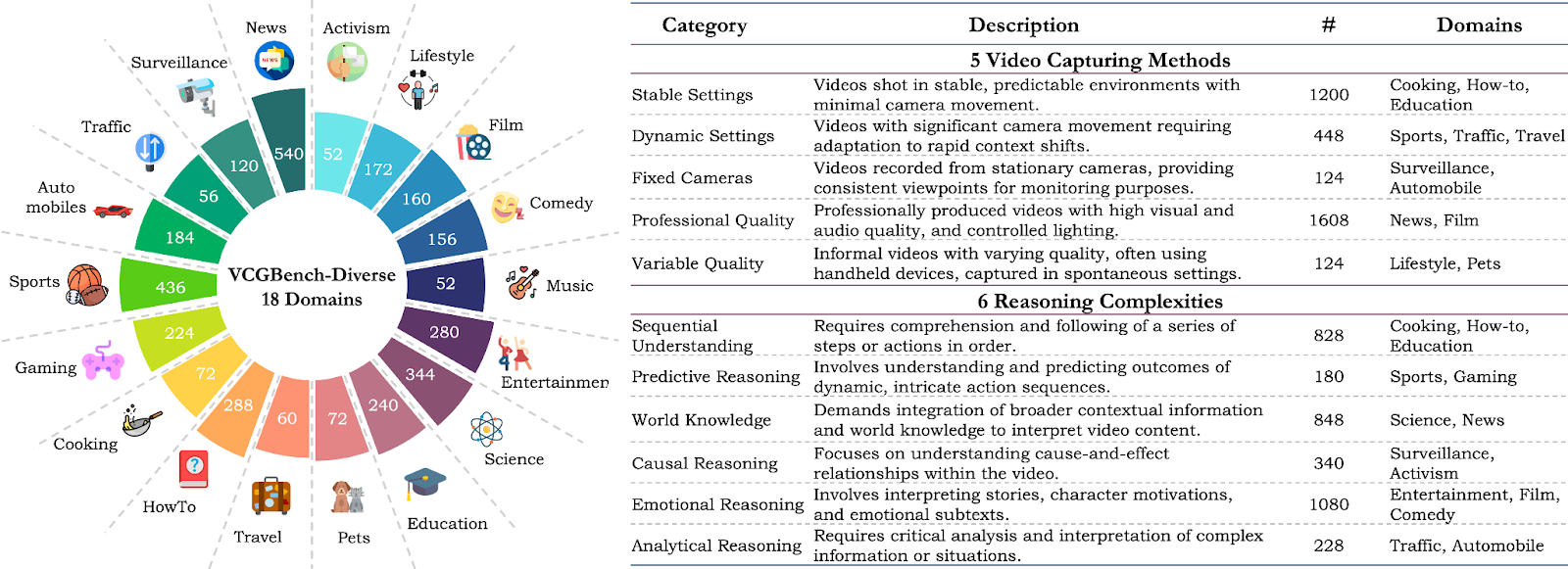
Figure 4: VCGBench-Diverse, a comprehensive benchmark for evaluating video language model architectures across 18 diverse video categories. It includes 4,354 QA pairs to test generalization in dense video captioning, spatial and temporal understanding, and complex reasoning, encompassing various video-capturing methods and reasoning complexities to assess analytical and comprehension skills.
Experiments
MBZUAI researchers conducted quantitative evaluations of VideoGPT+ on four benchmarks: VCGBench, VCGBench-Diverse, MVBench, and Zero-shot QA.
Implementation Details: VideoGPT+ uses the CLIP-L/14 image encoder and InternVideo-v2 video encoder, combined with the Phi-3-Mini-3.8B language model. The image encoder operates at 336×336 resolution, and the video encoder at 224×224. Training involves two pretraining stages and one instruction-tuning stage, with visual adapters being trained while other model parts remain frozen. For VCGBench, VCGBench-Diverse, and Zero-shot QA, 16 frames are sampled from videos. For MVBench, 8 frames are sampled due to shorter videos. The model is trained on various datasets, including VideoInstruct100K, VCG+ 112K, VideoChat, and WebVid, combining approximately 260K conversations.
- VCGBench
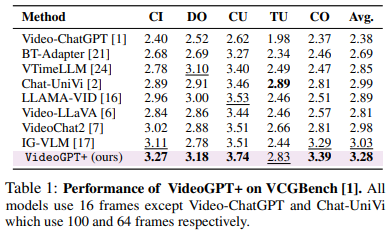
VCGBench consists of 3,000 QA pairs from 500 videos, evaluating responses on Correctness of Information (CI), Detail Orientation (DO), Contextual Understanding (CU), Temporal Understanding (TU), and Consistency (CO). VideoGPT+ achieves an average score of 3.28, surpassing previous methods by 0.25 (5%).
- VCGBench-Diverse
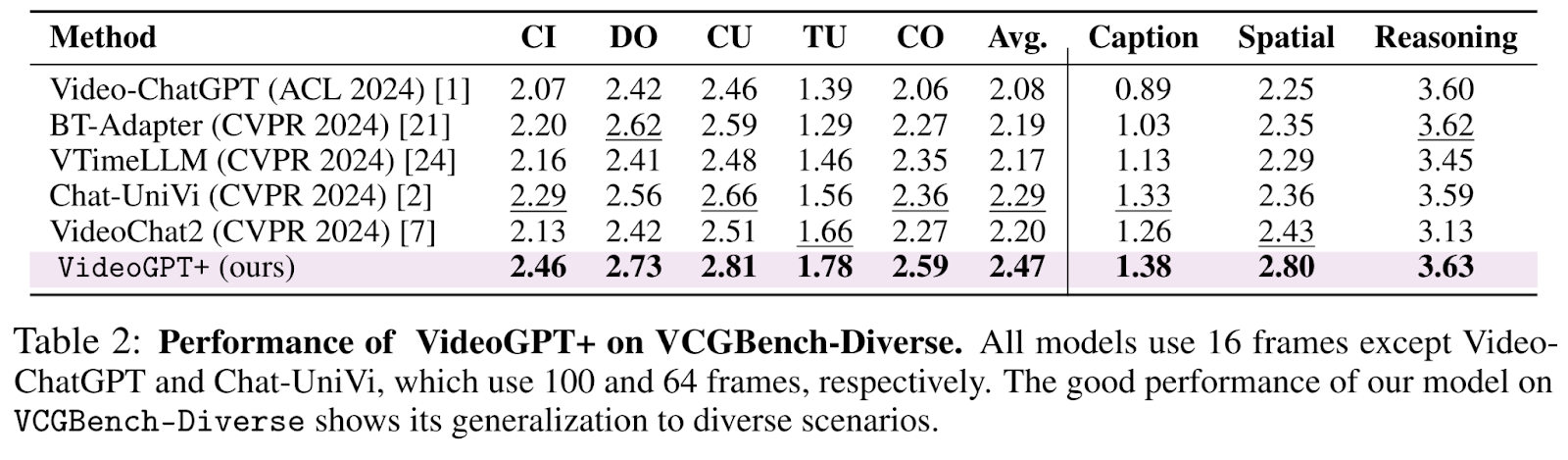
VCGBench-Diverse includes 4,354 QA pairs from 877 videos, evaluating CI, DO, CU, TU, and CO. VideoGPT+ scores an average of 2.47, outperforming previous methods. It shows significant improvements in spatial and temporal understanding, with gains of 7.4% and 4.6%, respectively.
- MVBench
MVBench provides 4,000 QA pairs from 11 video datasets. VideoGPT+ achieves a 7.6% overall improvement, scoring highest in 14 out of 20 tasks and second in 4. It shows significant gains in Action Prediction (+12.5%), Object Existence (+27.5%), Moving Direction (+17%), Moving Count (+29%), and Moving Attributes (+32%).

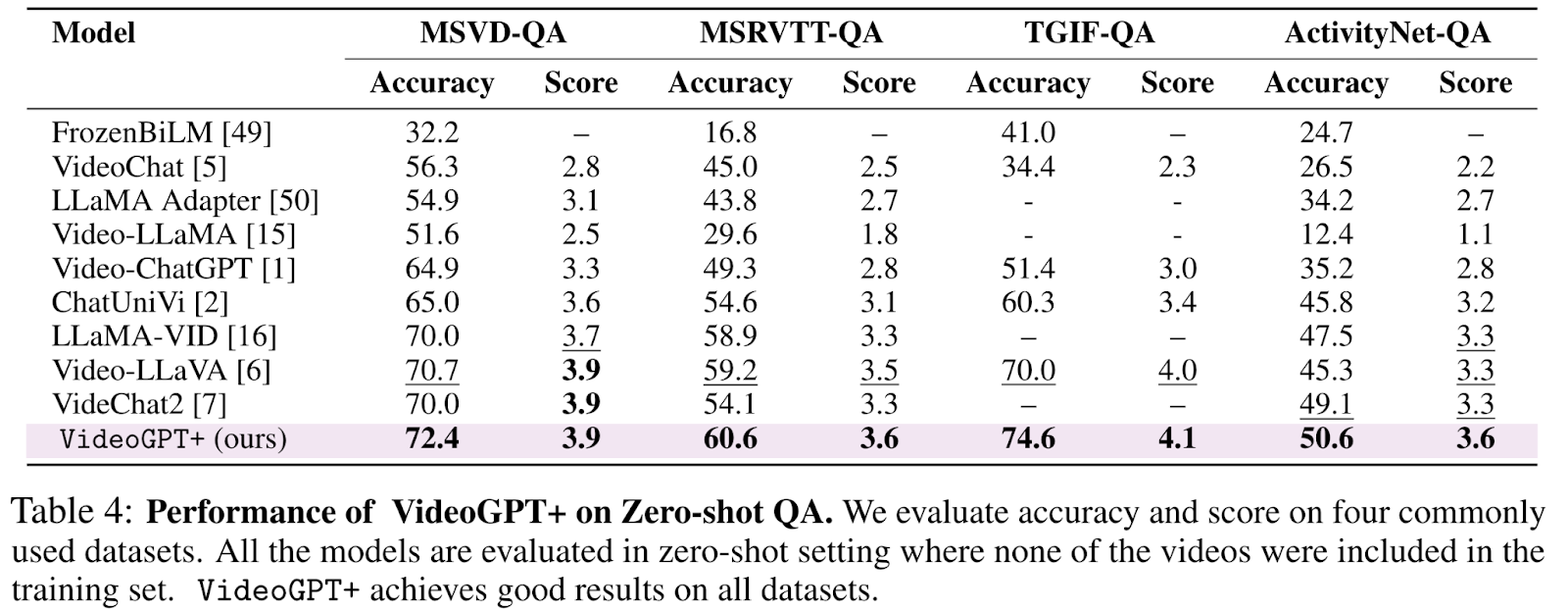
- Zero-shot QA
VideoGPT+ demonstrates superior performance on zero-shot QA tasks across four datasets (MSVD-QA, MSRVTT-QA, TGIF-QA, and ActivityNet-QA). This indicates its adaptability to unseen videos and accurate, contextually relevant responses.
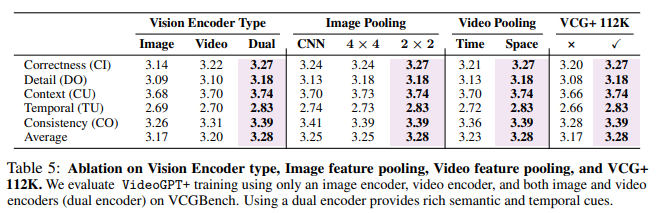
- Vision Encoder Type
Using only the image encoder scores 3.17, the video encoder alone scores 3.20, and the dual encoder design scores 3.28, showing the combined approach’s enhanced performance. - Pooling Strategy
Adaptive pooling for the image encoder performs better than CNN-based pooling. For the video encoder, space pooling preserves temporal information better than time pooling. - VCG+ 112K
Training with VCG+ 112K improves performance, especially in DO and TU, thanks to the novel semi-automatic annotation pipeline and enhanced instruction tuning data.
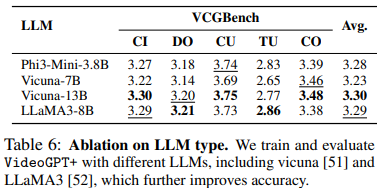
- LLM Type
Different LLMs, including Vicuna 7B and 13B, and LLaMA-3 8B, show slight improvements in VCGBench scores, with better LLMs yielding higher performance.
Qualitative Results
Researchers conducted a qualitative comparison between VideoGPT+ and the previous state-of-the-art method, VideoChat2, using an advertisement video featuring sunscreen.
Video Analysis: The video unfolds through several scene changes:
- It starts with a close-up of the sunscreen.
- It moves to a scene where a woman applies sunscreen to her hand, then transitions near a beach.
- Shows the woman applying sunscreen to her arms.
- Concludes by displaying the key ingredients and the sunscreen cover.
Performance Comparison
- Event Recognition: VideoGPT+ accurately identifies and describes all events depicted in the video.
- Advertisement Creation: Our model effectively crafts an advertisement highlighting the sunscreen’s dual function as a sunscreen and moisturizer.
- Product Details: VideoGPT+ correctly identifies the sunscreen’s SPF value and brand name.
In contrast, VideoChat2 struggles to capture all events and accurately identify the brand name.
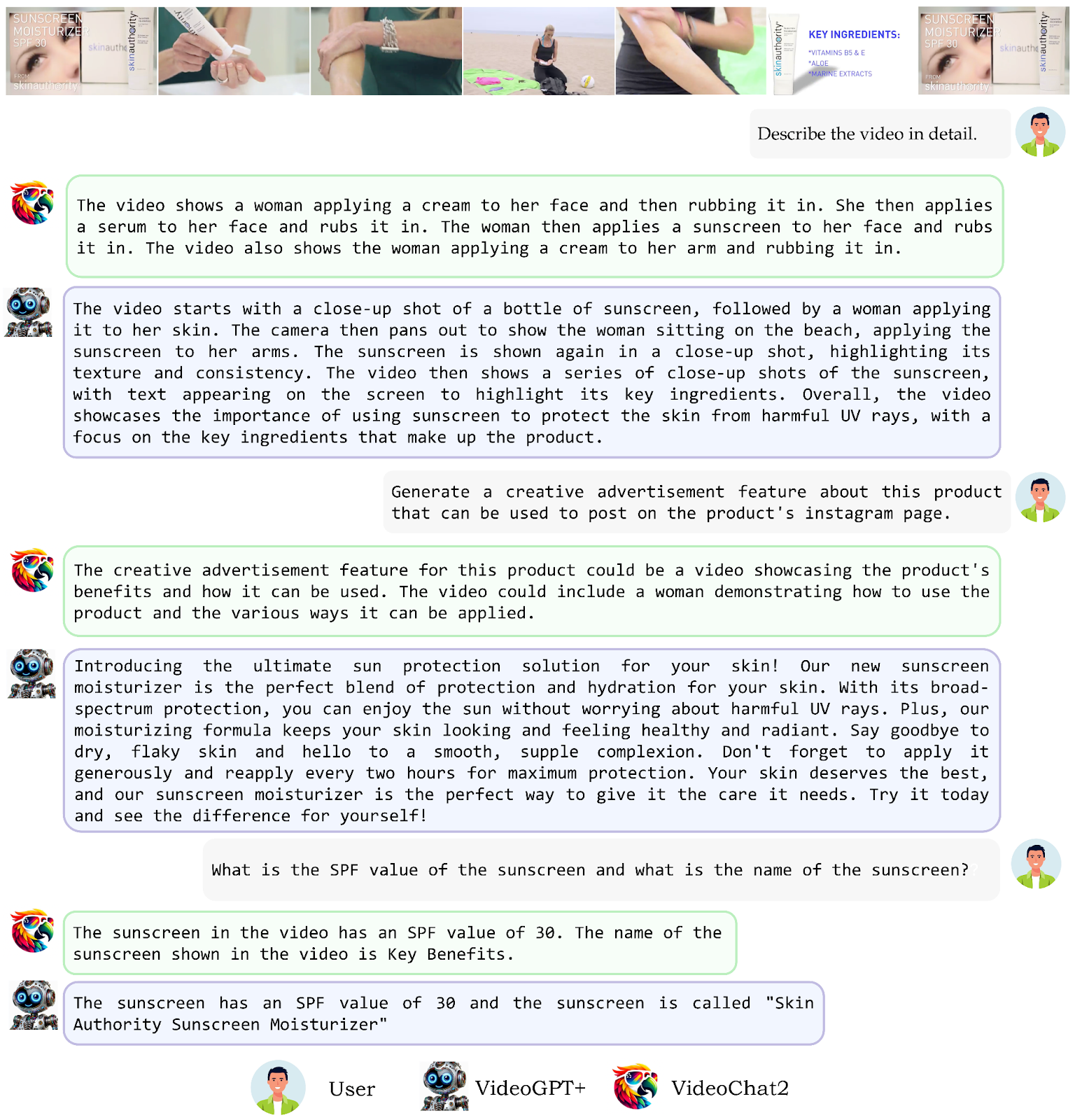
Figure 5: Comparison of VideoGPT+ with VideoChat2, demonstrating VideoGPT+’s superior temporal understanding by accurately identifying multiple events in videos, effective reasoning in generating creative advertisements, and precise spatial understanding in tasks like identifying SPF values and brand names of sunscreen products.
Conclusion
VideoGPT+ introduces a novel video conversation model integrating image and video encoders for enhanced video understanding. The model demonstrates superior performance across various video benchmarks due to its dual-encoder design and lightweight visual adapters. The project also developed VCG+ 112K, a large-scale video-instruction set using a semi-automated annotation pipeline for enhanced model performance, and VCGBench-Diverse, an extensive benchmark spanning 18 video categories, to evaluate video LMMs thoroughly.
Despite advancements, video LMMs still face challenges in precise action localization, understanding long videos, and navigating complex paths – all potential areas for future improvements. Check out our recent work on our complex video reasoning and robustness evaluation benchmark for Video-LMMs https://mbzuai-oryx.github.io/CVRR-Evaluation-Suite/ in collaboration with ETH Zurich, TU Munich and Google.
If you want to learn more about VideoGPT+, check out the resources below:
- Paper: https://arxiv.org/abs/2306.05424
- Code: https://github.com/mbzuai-oryx/VideoGPT-plus
- Offline demonstration: https://github.com/mbzuai-oryx/Video-ChatGPT/blob/main/docs/offline_demo.md
References
- Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Association for Computational Linguistics, 2024.
- Peng Jin, Ryuichi Takanobu, Caiwan Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- Ruyang Liu, Chen Li, Haoran Tang, Yixiao Ge, Ying Shan, and Ge Li. St-llm: Large language models are effective temporal learners. arXiv preprint arXiv:2404.00308, 2024.
- Yuanhan Zhang, Bo Li, Haotian Liu, Yong jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next: A strong zero-shot video understanding model, April 2024.
- Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023.
- Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.

No Comments